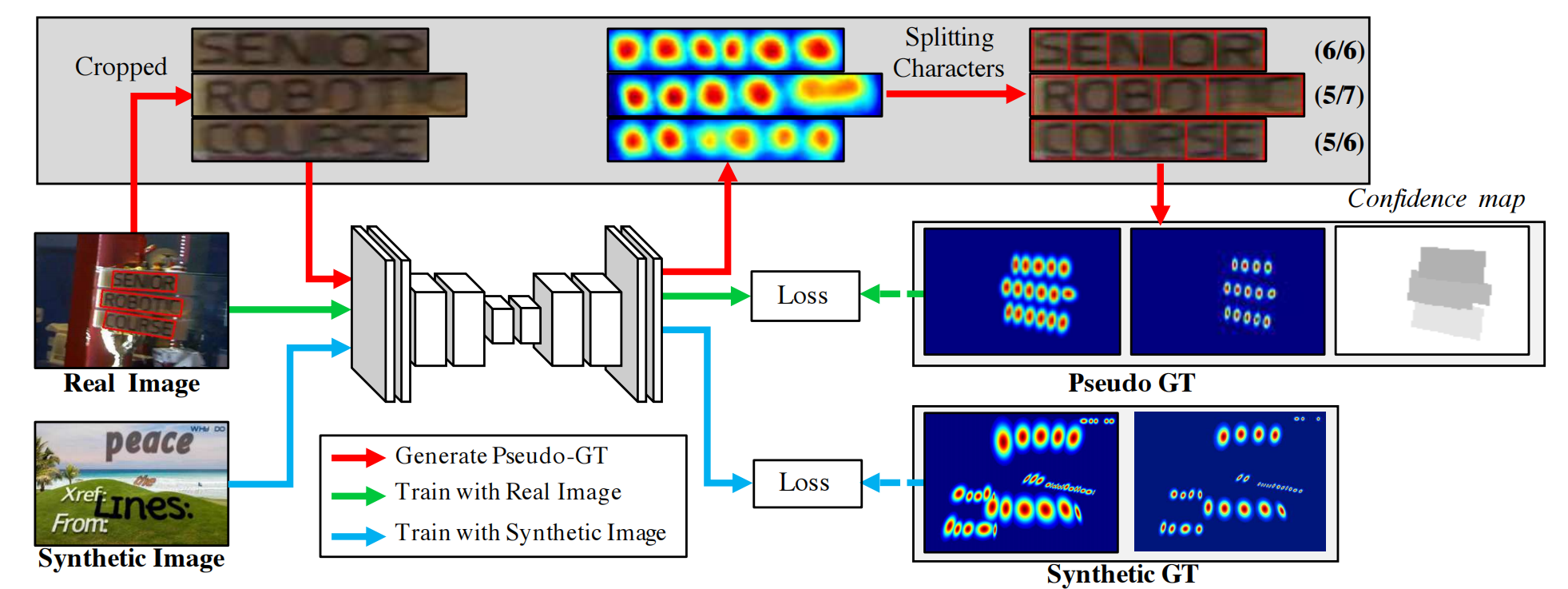
增值税发票自动识别
绪论
课题的研究背景及意义
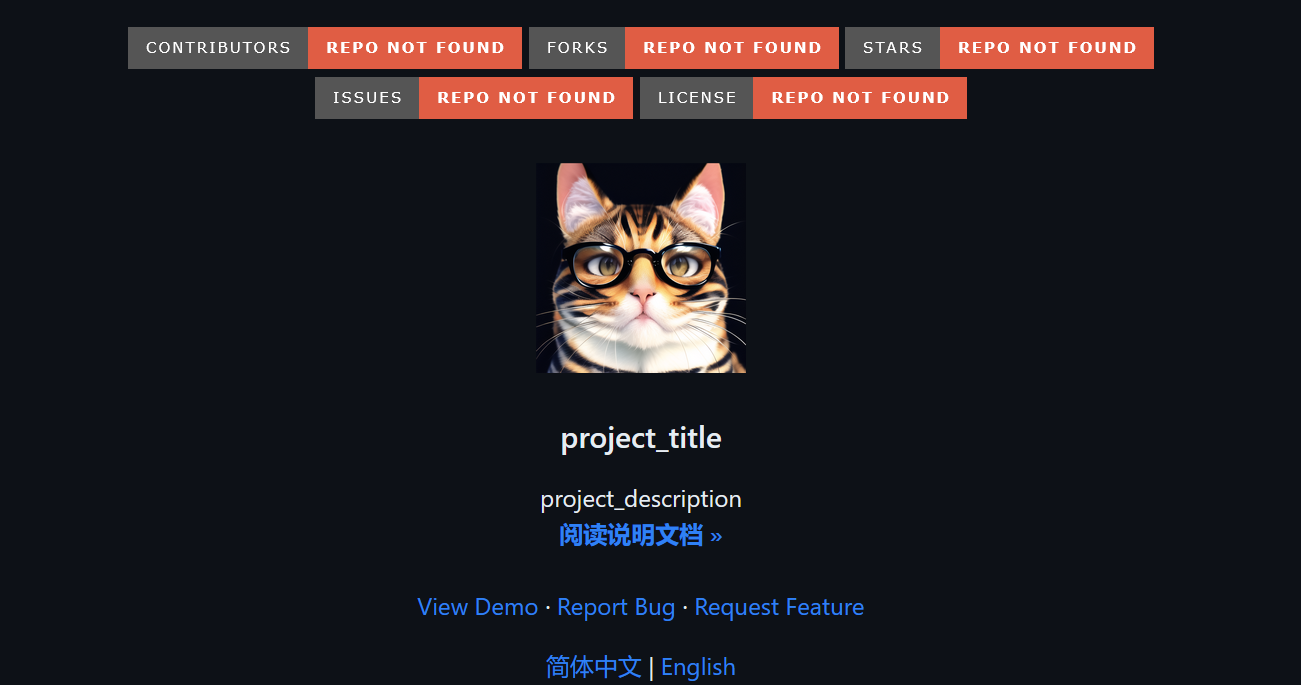
增值税专用发票是商业的行政单据[1],由于实现凭开具收据对购进费用扣税,而进货方要向商品销售方交纳所得税,所以它是完税单据,同时具备对商品销售方的税法义务和购物方进款税金的法律证实的意义,是有效所得税普征性和公平性的体现。因此,增值税发票的两大功能为交易凭据功能和缴税凭据功能。伴随着正在迅发展的科技水平和我国经济情况,在普通的日常生活中,增值税发票的投入使用,成为了不可避免的一个环节,对于增值税发票的需求越来越多。作为普通情况下,收据的一个不可缺少的部分,增值税发票包含的信息,涵盖了以下的几个方面:发票应用代码、花费所产生的金额、购买商品的数量、商品的价格、一张发票的号码、不同纳税人不同的识别号等,下图中显示的增值税发票为一般形式:
在当前移动互联网快速发展的大环境下,增值税发票识别成为一个比较热门而有价值的应用方向[2]。并且伴随着社会信用体系不断完善,增值税发票已经成为人们主流的交易证明。在工商业和农业制造技术、现代应用科学技术、军事领域科学科技、医疗领域识别技术等领域[3],逐渐涌入了大量使用图像信息识别这一技术的人们,尝试以此来认知识别和评判估计一系列的事件,并根据所产生的结果,来处理解决现实生活中会遇到的实际问题,在此环境条件下如何高效有序地对增值税发票进行智能化管理,是对当下智能票据提出的一个硬性要求。发票号码作为发票唯一的身份标识,常用作支付交易证明和经费报销申请的主要依据,所以针对发票识别技术(Invoice Recognition Technology,IRT),从传统的机器学习到当下的深度学习都在不断地进行着算法的更新与迭代。这样在当今信息科技高速发展的年代,数以万计的人们对于增值税发票识别的信息处理技术产生了更加深入的要求,人们希望识别的信息处理技术能够较为迅速且兼顾一定的精确,来检测识别索引出人们所需要的一系列图像或文字信息。
目前,CVPR、ICCV、ECCV等全球顶尖学术会议中[4],已把现场文字检查与鉴别技术作为其研究重点专题之一[5],字检查与识别技术广泛使用于图像识别方面,是当前科学研究的前沿问题。而现场图像识别技术(Scene Text Recognition,STR)是在某种复杂情形下将图形输入并翻译成自然语言的,需要同时包含文字检查与图像识别二种过程,通过文字检查即发现了图像的地址与区域,通过图像识别即将文字区域信息转换为文字信号。图像识别技术对于人们而言是十分富有挑战性的技术,虽然目前图像识别技术发展缓慢,但是人们仍然希望将实现技术普遍运用到日常生活中的各个方面,并不断地在为之努力着[6]。因为文字辨识技术发展不仅促进了其他科学技术的进展,并且文字判辩识别技术的进步空间十分宽广,能否于的应用领域也十分广阔,其中光学字符识别(Optical CharacterRecognition,OCR)的辨识技术在文字辨识领域中是项关键性科技。
发票识别检测的主要目的是从复杂的发票布局环境中检测出发票的有效区域。通过Sobel算子进行发票边缘检测 。在步入二十一世纪以后,由于电脑计算能力技术进行了很大的提高,深层神经网络和电脑视觉信息技术也开始运用在了发票文字信息检索之中,其中比较成熟的是基于卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)和链接主义的文字建议系统(Connectionist Text Proposal Network,CTPN)[7]实现的算法。
一般的发票识别技术是由预处理和图像输入构成的,预处理技术包括了灰度化和二值化及图象修改更正,以及消除噪声等等,而图像则是,应对不同情况下的的压缩技术,提供了不同情况的存储技术。而对于怎样判断出发票的识别性能好和差的指标分析,则涵盖了产品的误识性、识别速度、可行性、可靠性和易用性等多个不同的方面问题,并通过运用一些辅助工具数据信息能够进一步提高鉴别的准确度等,这在发票的实际应用上是十分关键的。简单的来说是先将文本转化成图像信息,而后再运用字符识别技术把图形的一系列信息来转换成符合应用方面的输入技术。然后再依据发票鉴别判定识别的产生结果来进行对应的分析,并通过智能纠正错误信息系统。随着我国的科学技术发展得愈来愈好,发票识别技术也被广泛使用开来。
在现实应用中,发票文本的检查和鉴别工作通常串联在-起,能同时检查到文本位置并对其加以鉴别的方式,被称之为”端到端”文本辨识方式。但是由于在中文场景中往往存在着背景干涉、图片朦胧、文字遮蔽等一系列的复杂情况,所以在中文场景文本鉴别上也面临了更多的挑战,由于各种类型的发票开具所提供的文字图片尺寸、颜色等所给出的条件均截然不同,因此在本文识别情况下,最先使用的技术就是分类,以确定发票所提供的类型,这样对于如车票、小票等,这些文字元素和图片元素固定的发票依据所给出的不同信息,就可以利用已固化的特征模板,从而来截取出,即将需要进行识别信息中的所有文字和图片,同样的,这一举措,也同步大大减弱了之后识别步骤的难度。而接下来,面对增值税这些机器打印形成的图片和文字,而随着机器的转子速度不同而发生变化的发票,将引入采用文字图像增强的二次分割法,并完成文字截取,并完成倾斜校对。这既减少了辨认困难,也增加了发票辨认的准确性。
目前,文本检索方式一般分为根据文本内容选框回归的类别、依据划分的回归样式以及其划分和回归样式组合的方式。尽管在最近的几年中,源于深度学习的文本字符测试识别技术逐渐取获得了伟大进步,但文本字符作为具备其独特拥有特征的一个目标对象,其文字构成结构、不同色彩、不同方向、不同大小等至今依旧会呈现出多元形态样式,所以针对于普遍的目标测试技术,实现起来仍旧较为困难。假设一个已经在大数据集上产生了十分不错的效果的模型,将该模型投入应用于另外的大数据集上的效果也并不能达到我们需要的效果,甚至说情况是非常糟糕的。由于大多数模型都是通过某项数集来调整系数或进行进一步调整的,并且由于其极大依赖于实验数据,在充分了解后也并不能获得实质性的认识,所以该课题很值得深入研究。神经网络模型在文本测量方面也已经有了研究,如区域建议网络(Region Proposal Network,RPN),如果仅仅使用RPN的技术来测量文本,那么很难十分准确地实现水平测量的效果。RPN的方法是通过训练来直接定位图象中的文字行为,不过利用文本行为来估计图象中的文字发生错误的可行性较大,因为文字是一种缺乏明显的封闭边界的序列。值得高兴的是,Anchor回归机制的发明使得RPN能够通过单尺寸窗口测量更多尺寸的对象,这种思想的核心内容就是通过使用些灵活的Anchors在大尺寸和纵横比的区域里对物体大小作出估计。其研究结果,通过CTPN方法,构建了增值税发票的文字检验神经网络模式,可以更精确地对增值税发票的文本内容进行全水平检验。
OCR研究进展
光学字符识别(Optical Character Recognition,OCR)是模型辨识技能中的一种旁支,目的是在图片处理过程中的信息进行光学处理,提取并直接输出图像的所有文本信息。如今的OCR包括传统的OCR和场景文本识别(Scene Text Recognition,STR)[8],这两种识别技术中使用的内容,涵盖了所有的文本字符信息检测技术和识别技术。现有的OCR分为三种方法:
(1) 文本字符检验测试识别方法,作用于检测识别和定位确定图像中需要识别文本的位置。
(2) 识别方法,将检测到的文本区域转换成语言符号。
(3) 可以进行文本检测和识别的端到端方法[9]。
文本检测方法
文本检测是文本识别首先要做的一步,要让机器识别自然场景中获取的文本信息,要先让机器知道文本信息的位置。现在也有很多文本检测的解决方案,但是在面对复杂的图像时,往往抗干扰能力不尽如人意。而且这些图像通常会有不同字体(例如艺术文字),不同形状,严重影响了文本的检测与识别。
文本识别方法
机器获取文本位置以及形状后,就要开始主要工作文本识别。在近期以来,世界范围内的各界人士,都已经见识到了神经网络的强大力量和它进行的巨大复兴,这最先需要提及的,是在深层神经网络模式的基础上,特别是深度卷积神经网络(Diffusion Convolutional Recurrent Neural Network,DCNN)在各种视觉应用上的巨大成功所带来的。
在实际中,场景文本通常以递次的情况出现,而不是单独地呈现。和常规的标识有所不同,标识这些相关系列的对象一般都必须系统地预测一些对象标志。所以,这些目标的辨识可能被认为是顺序辨识问题。
端到端的方法
端到端的方法,在进行模拟练习时需要使用检测功能的识别模块,从而利用最终的识别结果提高整个模型的精度。一部分模型,比如统一网络的快速定向文本搜索(Fast OrientedText Spotting With A Unified Network,FOTS)和明确对齐和关注的 “端到端 “的文本挖掘器(And-to-end Textspotter With Explicit Alignment And Attention,EAA),连接了流行的文本检测和文本识别方法,并用一个损失函数统一训练它们。掩膜文本观测器(Mask Text Spotter,MTS)[10]利用设计的模型,将文本识别转换为了一个语义分割问题。
论文的主要内容及结构安排
本文主要内容为基于深度学习的增值税发票自动识别。本文第一章为绪论,介绍了增值税发票自动识别的课题背景;第二章介绍现在应用的文字检测和文字识别相关技术;第三章分析增值税发票自动识别系统的需求并进行总体的设计;第四章为实验过程及结果。
相关理论及技术介绍
卷积神经网络
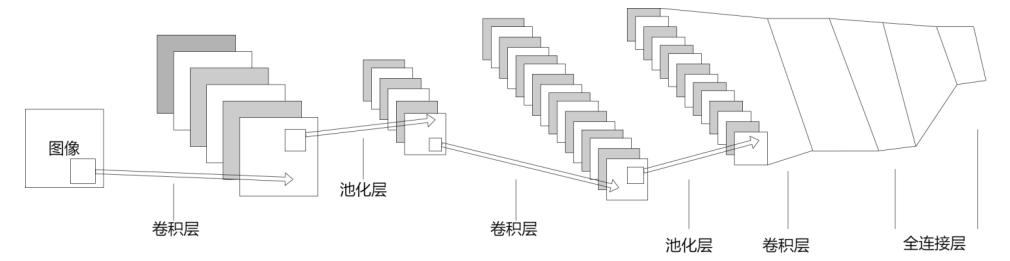
人工神经网络(Artificial Neural Networks,ANN)是一个采用模拟仿真传统生物学情况下的人体神经系统活动而进行构造的一个网络,以实现分布式网络并行数据处理的统计数学模型。ANN系统通过调整人体内神经元和神经元之间的权重关系,从而达到了处理信号的效果目的。而作为一种十分典型的前馈神经网络的卷积神经网络(Convolutional Neural Network,CNN),其架构主要由若干户卷积运算层和池化层所组成,特别在影像数据处理方面以CNN中的特点体现得最为明显。
一个CNN的最本质的组成是由全接口层、一个输出层、池化式层(pooling layer,也称作取样层)、入口输入层、再加上卷积式层(convolutional layer)等拼接组合而成。逐点卷积方法计算层与池化层之间的连结方法通常均是若干个,因而选择了逐点卷积方法计算层与池化层之间的连结方法,也就是每一个逐点卷积方法计算层需要最先连结一个池化式层,之后每一个逐点卷积方法计算层再被一个池化层连接而成。即由于一定的局部或整体联系,在卷积法计算层内的特征图的所有神经元均与其输入发生,并通过相应的连接权数对该部分系统数值完成了加权求和之后再乘以偏置值,因此获得了该神经元的全部数据,这种步骤也就等同于了卷积步骤,CNN就因此而命名。
循环神经网络
循环神经网络(Recurrent Neural Network,RNN)主要有以下3方面的优点:
(1)RNN有强大的捕获序列和历史数据的特征。相对独立的每一条序列,可以通过上下文进行比较处理更有优势。
(2)RNN可以和 CNN组成一个端到端的整体模型,通过误差反传一起进行训练。
(3)RNN不受序列长度的限制,可以对任意长度的序列进行处理。
长短期记忆(Long short-term memory,LSTM)是一种属于十分特别的特殊RNN,由于阶梯消失问题和阶梯破坏问题较为严重,于是针对于长序列训练中的这些问题,而提出并实现长短期形式记忆。简单而言,即是在和普通的RNN对比过程中,LSTM可以在更多序列中产生比较好的结果呈现。
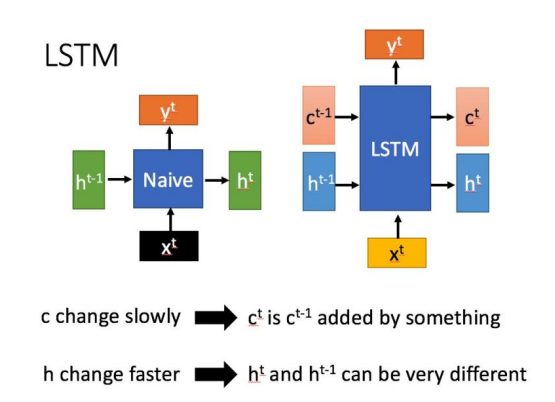
CTPN神经网络简介
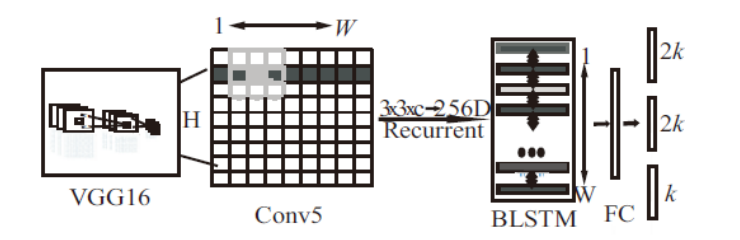
CTPN的神经式网络运行模块,一般情况下会包含以下这三个部分:单卷积方法的计算层、双向的长短期记忆层以及一个全连接层。底层利用VGG16的提供特性,可以使用下一个 类型长宽高比例的conv5的特征图feature map,一个长宽比为3×3的空间视窗[11],并在完成一次卷积计算(VGG16 的conv5)的feature map上滑动视窗。不同行中的顺序视窗之间通过双向长短期记忆神经网络 (bi - directional long short - termmemory,BLSTM)循环连接,并且每一个视窗的卷积特性(3×3×C)作为BLSTM 的输入入口,再进行双向BLSTM,以此达到对相互关系的序列的信息理解与学习过程,并利用VGG将最后一卷积层提供出来的feature map 转换为向量的类型,来作用于接下来的BLSTM训练场景。紧接着将 BLSTM的输出出口再输入至FC中,最终模型提供:2k个anchor 的文本/非文本分数、2h个y坐标、h个side_refinement(侧向细化偏移量)[12]。根据该模式而设计的CTPN神经网络模式,如图2.3所示。
类型长宽高比例的conv5的特征图feature map,一个长宽比为3×3的空间视窗[11],并在完成一次卷积计算(VGG16 的conv5)的feature map上滑动视窗。不同行中的顺序视窗之间通过双向长短期记忆神经网络 (bi - directional long short - termmemory,BLSTM)循环连接,并且每一个视窗的卷积特性(3×3×C)作为BLSTM 的输入入口,再进行双向BLSTM,以此达到对相互关系的序列的信息理解与学习过程,并利用VGG将最后一卷积层提供出来的feature map 转换为向量的类型,来作用于接下来的BLSTM训练场景。紧接着将 BLSTM的输出出口再输入至FC中,最终模型提供:2k个anchor 的文本/非文本分数、2h个y坐标、h个side_refinement(侧向细化偏移量)[12]。根据该模式而设计的CTPN神经网络模式,如图2.3所示。
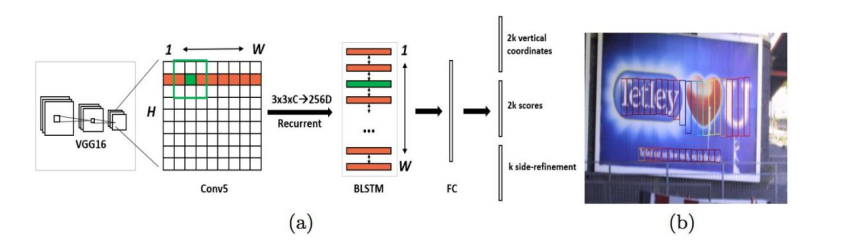
原始的CTPN系统只检测以横向顺序排列的文字。CTPN结构形式和FasteR R-CNN[13]结构形式的基本类型相同,只不过在基础上增加了LSTM层的这个环节。
假设输入Image:
首先从VGG[14]中提取特征,可以得到大小尺寸为的 $N \times C \times H \times W$ 的conv5 feature map这个特征图。
之后在conv5有长宽比例为$3 \times 3$的滑动视窗,也就是将各个节点都根据周围尺寸为$3 \times 3$的地域特点,而得到了一条直径为$3 \times 3 \times C$ 的特征矢量。对于输出的$N \times 9C \times H \times W$ 的feature map,这些特性显然是可以通过CNN了解到的空间特征。
再将这个feature map进行Reshape,
然后,将所有的以$Batch=NH$ 且最大时长$T_{max}=W$ 的数据信息流进入双向LSTM[16],并了解每条行的顺序特点。经过双向LSTM输出$(NH) \times W \times 256$ 之后,再经Reshape回复原来状态:
CRNN端到端的识别
本文选取了卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)作为识别模型(主要由CTC、CNN、RNN构成),在使用该模型的情况下,能够进行识别出不定长的文本序列。作用于具体的应用阶段的时候,CNN则进行文本字符图像的特征提取工作,而RNN则依据Bi-LSTM来进行融合特征向量工作,再进行提取文本字符序列特征这一工作,最后通过CTC这一转录层来输出不同序列的概率分布情况,借此来预测最优的文本序列值。另外,由于CRNN摒弃了在传统神经网络中采用的完全连接的方法,所以也产生了更为紧凑和合理的模型。所有的这些特征,使得CRNN成为了基于图像的序列辨识的最好方式。
CRNN的优点
CRNN的网络结构是专门为解决图像中的序列而设计的。因为将CNN和RNN进行了结合,CRNN有以下几个优点:
(1)相对于CNN,能够实现在序列数据中直接进行学习功能,与CNN对比者不需要较为细致的字符级的位置标注这一内容。
(2)本该进行预处理的CRNN的图像数据,不需要在输入到其中的时候进行处理,也不需要进行手工的特征提取,就可以从图像中直接学习到相关的特征。
(3)CRNN因为含有RNN,可以捕获图像特征序列中上下文的依赖。
CRNN的网络结构
如图显示,CRNN的网络模式,CRNN由三个部分构成,包含最常用的卷积层、循环层以及翻译层。CRNN主要提出了在文字识别中是对文字序列加以预测的思路,它首先利用了CNN技术将文字图像的特点加以提炼,而后再利用RNN网络对其特征加以文字序列预测,最后再利用了CTC损失函数的翻译层,得出了最终的结论。CRNN虽然由各种网络结构所形成,但依然可根据每一种损失函数加以系统训练。
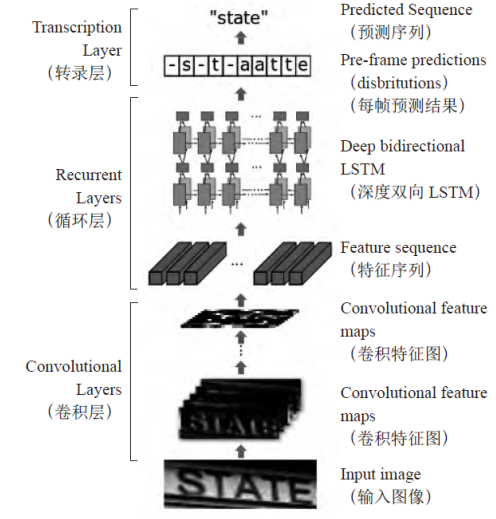
特征提取,正常的图像采集,所获取到的特征通常以序列方法传递。
BLSTM,特征输入到BLSTM,输出每个序列代表的值(这个值是一个序列,代表可能出现的值),对输出进行softmax操作,等于每个可能出现值的概率。
CTC,是一个LOSS,一个从概率到实际输出的概率。
CRNN的创新之处就是可以通过双向BLSTM来获取图像特征信息,对序列特征识别效应更显而易见。以及把语言识别领域的CTC-LOSS导入图像,这是质的突破。
在文本识别基础上的试验证明了,和传统方法或其他基于CNN和RNN的算法比较,CRNN方法拥有着卓越并具有竞争性的特点。
CTC模型
CTC模型[16]。连接时间分级法(Connectionist Temporal Classification,CTC)也叫连结主义时间划分,主要用于处理进入顺序与产出顺序之间无法一一对接的提问。通过CTC,可以将循环层生成的每帧预期结果概率值转换成标签顺序,之后再开始执行输出,使进入顺序与产出顺序更加平整完善。在此模式上,CTC可视为依据输入的每帧预测信息,找出带有最大概率值的标签顺序并执行输出。因此CTC的损失函数应该界定为:
系统分析及总体设计
增值税发票自动识别系统分析
由于最新的深度学习卷积式神经网络技术,在许多电脑视觉任务中的性能已超越了传统方式,尝试在发票系统中使用神经网络模型替换传统的算法完成目标区域定位任务,为了更好满足比传统算法更好在检测速度与检测精度之间作更好的平衡,且相对于传统图像匹配算法具有更好的鲁棒性。本项目在传统的CNN和RNN中,引入了CTPN和CRNN技术,通过更加深层的神经网络和预测识别,来实现针对于增值税发票场景下文字的识别。
增值税发票自动识别算法设计
本项目根据增值税发票版面的一些固定特有的特点,从而构思设计出对于数据对象类的一系列识别算法流程,算法流程设计过程如下图所示:
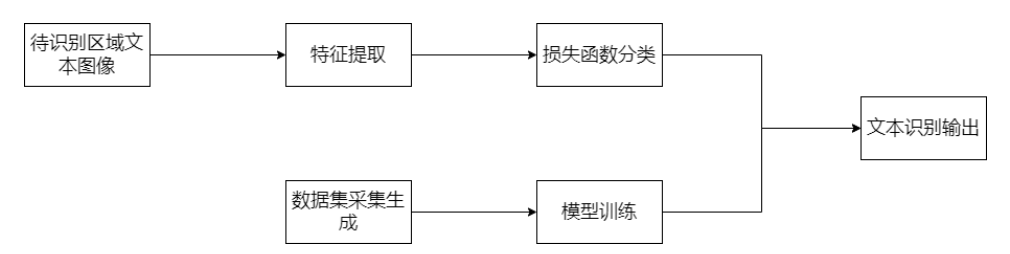
系统环境配置
在该项目中,我们使用是是Windows系统、Pytorch、Cuda、Python的组合。首先我们需要将环境配置成功,才能为我们需要的项目,提供一个良好可以运行的稳定环境,以此来进行接下来我们需要进行的文本字符识别、数据集采集工作、文本字符训练工作、文本字符运行等等的工作。以下为项目详细数据。
| 项目 | 参数 |
|---|---|
| 操作系统 | Windows 11 专业版 21H2 |
| CPU | AMD Ryzen 7 5800H |
| GPU | NVIDIA GeForce RTX 3060 |
| RAM | 32G |
| 深度学习框架 | Pytorch1.10.1 + Cuda11.1 |
| 编程语言 | Python3.9 |
首先,该项目使用Python编写完成,所以我们需要在我们的电脑上搭建一个Python的运行环境,在这里我们采用较为新的Python3.7版本。之后项目运行环境,我们可以根据Anaconda进行虚拟环境的设置,但是前提是操作系统需要一个Python环境,所以我们需要进行下载。采用3.7是因为这个版本较为稳定。
在这里,我们需要访问Python文件提供的官网,来进行下载。
因为我们的操作系统是64位的,所以我们需要下载64位的Python3.7才行。然后根据文件提示,我们一步步进行安装即可。
然后进入终端进行查询,我们可以看到,Python3.7.4已经安装完成。
然后是Anaconda的安装和部署,这里一开始和Python安装一样需要去下载文件。
在这里,由于外网访问的限制,所以我们通过访问清华的开源镜像网站来进行下载。
同样我们需要跟着安装文件的提示来进行安装,最后在终端中进行查询是否安装成功。
然后我们需要安装对应的Cuda文件,我们才可以调用我们的显卡,来进行数据集的训练工作。
我们将文件安装在默认位置即可。安装完成之后进行查看时候安装成功。
然后是Conda环境的激活配置。
首先我们需要查看一下显卡的驱动版本,这里可以看到驱动的版本为10.2.89,符合Conda和Pytorch的要求,可以在此环境下运行。
然后进行环境的激活,可以看到,这里显示环境激活失败。

寻找原因之后,发现是软件包的数据源出现了问题,因此我们需要将数据源进行替换,这里我是用清华的开源镜像网站进行替换。
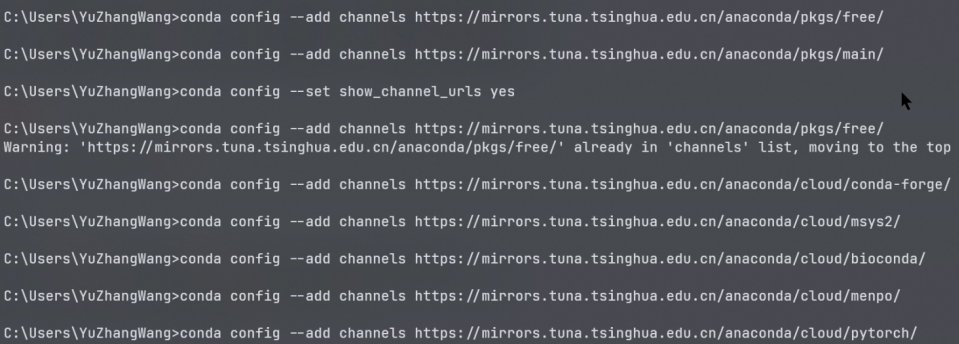
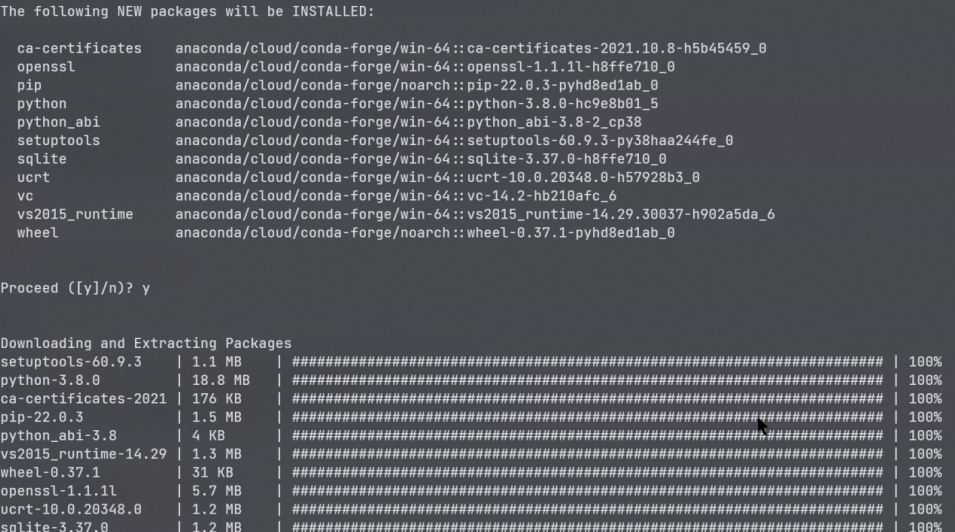
然后进行环境的创建,可以看到,此时环境创建工作在正常运行。

这里会将需要的一些依赖库进行导入,为创建环境提供基础包。
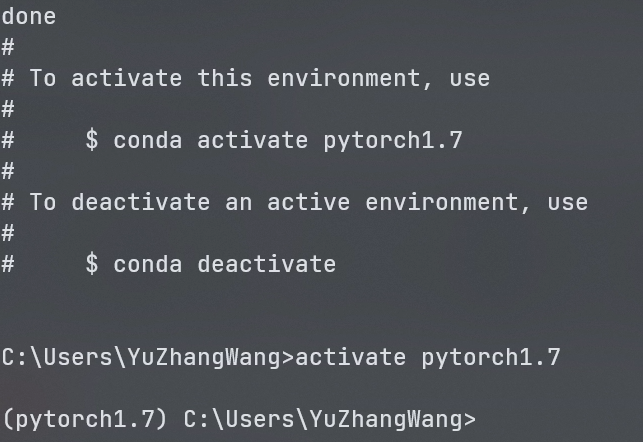
可以看到提示,Pytorch1.7的Conda环境已经创建成功,然后即可进行激活,可以看到,开头变成了Pytorch1.7,着代表已经进入到这个环境当中。
然后需要安装Tor和Cuda适配的版本,但是此处安装结果显示为失败。
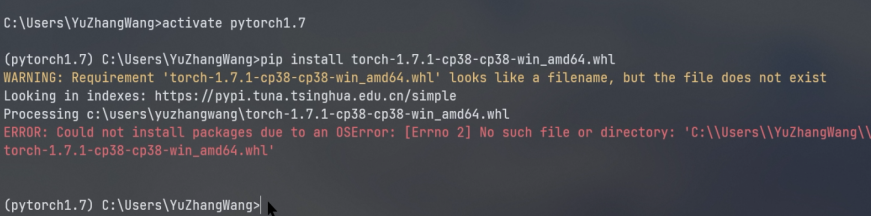
经过判断,可以发现问题来源于下载包Tor版本和Cuda版本不对应,导致适配问题一直出现,所以此时根据版本的对应关系,需要下载正确的包,并进行安装。
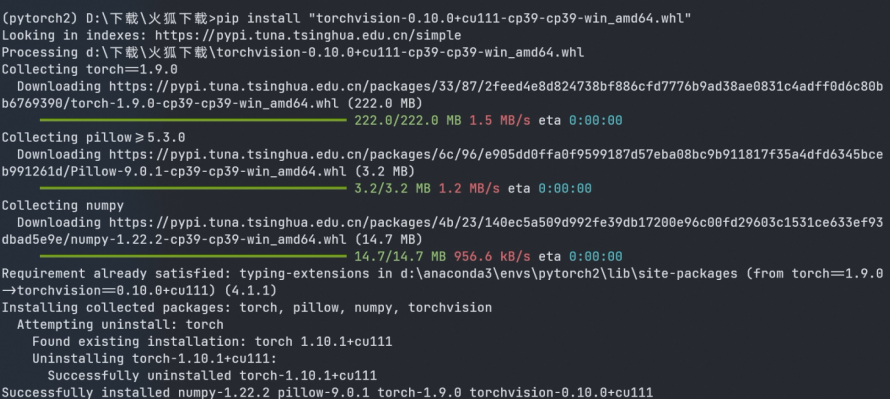
这里两者关系对应存在一些问题,所以Pytorch1.7版本也需要进行对应更换,这里将版本替换成1.10版,随后在Pycharm中,选择解释器为新创建的Pytorch环境。
在选择完成之后,进行等待,等待后台Python解释器更新完成,并且生成框架索引。
更新之后,进行测试,发现还有没有安装成功。
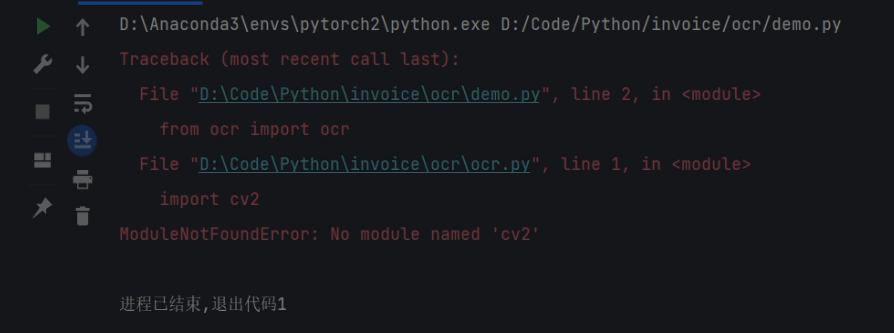
此时需要进入终端,并且输入activate pytorch2来激活新创建的环境,进入到这个创建的虚拟框架当中。进入之后,输入pip install opencv-python来导入缺失的包。
在进行测试的时候,可以看到,下方Python解释器成功导入,并且框架也正在导入。运行测试之后,也能正常运行起来。

数据集加载
数据集的选取,可以说十分重要了。一个好的模型训练,需要大量的数据集,这些数据集不仅在数量上需要要多,同时也要求,从多方面、多角度、多个形态样式来选取数据集,这样可以保证数据集在训练的时候,能够尽可能完善地训练出我们需要的模型来。
项目需要选取一个有效的数据集,而开源平台提供了一系列的数据集,这里选取的Pascal VOC挑战赛所使用的数据集,用于构造建立和评判估计文字分割、文字对象检测和图像分类的算法。但是由于其官网一直处于关闭的状态,所以我们需要访问镜像网站来获取其资源。

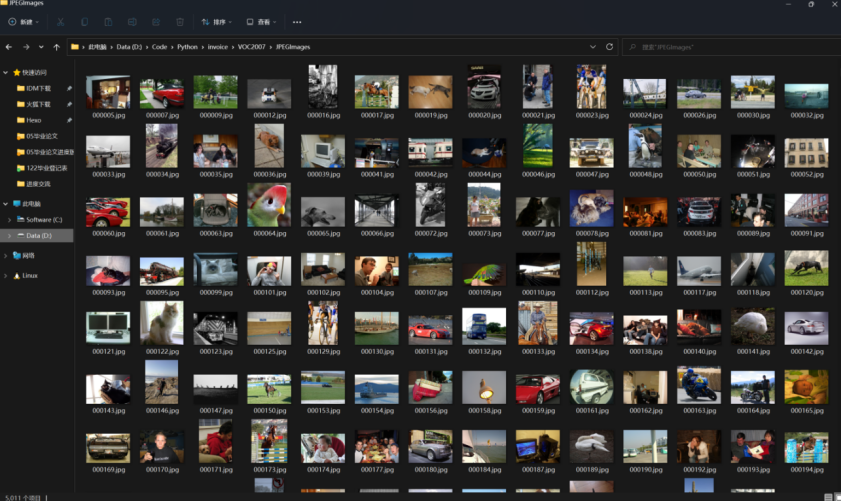
这里需要的是数据集中的图片和坐标数据,其中图片信息如下,是一系列日常生活中的照片,一共是5011张,一般数据集的选取,在2000个至10000个左右合适,5011张正好在此区间内,因此适合用作数据集。
另外一个需要的是图像的坐标文件。例如一张带有椅子的图片,它的数据坐标中就包含了数据来源信息,长度高度和深度信息。
1 | <source> |
例如以上为第五张图片的部分坐标信息,从这里可以读出。首先,数据集来源为VOC大赛提供的开源数据集,图片的验证id信息。其次是宽度、高度和深度,例如这里的宽度为500、高度为375,深度为3。然后就是椅子的位置信息,这里是将图片类比于一个框,距离边框的大小,来确定椅子大概可能出现的区域,对其做出一个预测。
在代码中体现为,设定两个元素,img_dir和xml_dir来存放数据集的存储地址,如下所示。
1 | img_dir = os.path.join(base_dir, 'D:/Code/Python/invoice/VOC2007/JPEGImages') # VOC数据集路径 |
文字检测网络
对于一个OCR识别的项目来说,能做到提取图像中的文字,并转换为文本形式,以供后续任务使用。从图像中提取文本分成了两个部分,一个部分是检测文字所在的位置,另一个部分是识别文本区域内容。检测文字所在的位置就是CTPN,实际上文本检测也属于物品检测,只不过文本和常规的物体有着较大的区别,再加上增值税发票较为复杂的情况,所以文本检测相对于一般的检测来说,较为复杂。
CTPN网路架构可以分成,进行VGG特征提取;LSTM融入上下文信息,这一步是为了进行信息的预测,比较强调时序的问题;基于RPN完成检测。
首先要解决前景和背景的二分类问题,一个VGG提取模块,将原本的一个图片,分成不同层次,再进行池化操作,再经过了一定次数,例如64次之后,特征图中一个像素对应原始输入的多个像素。例如16个。
然后是ANchor大小选择问题,由于是文本,因此此时宽度是需要固定的,而长度是可以进行自由选择的,例如这里选择10个像素作为宽度展现。
在输出的结果中包括了2k得分、2k回归和1k边界调整。其中边界调整能使得文本检测框效果更好。
CTPN网络检测到的每一个小块文本区域还需要拼接成完整的文本区域。因此需要建立一个规则,分前向和后向两部分,前向向前走,对于Xi,基于重合度与位置距离的一定像素点找到Score值,也就是最大的$Xj$值,接下来再往回进行检测,检测规则依旧不变,比较两次得分值大小以此来判断序列。
文字识别网络
CRNN是文字识别的一个经典模型,它是一种卷积式的循环型神经网络结构,图像的序列识别情况比较适合用这个算法模型来解决,尤其是场景文本字符识别,因此发票识别采用此种算法较为适合。
CRNN实现分成了几个部分,我们一个个来进行说明,最先需要说明的是卷积层,也就是CNN,在这一层中,特征信息是所需要的,需要使用一定的方法将其提取出来,然后需要将其进行表示,表示为特征向量。之后就是循环层这样层的工作,这里的循环层是Bi-LSTM,是将其提取到的信息放入一堆RNN中,每个特征序列都是由双向LSTM从识别特征向量中组合而成,在此之后,那么关于特征向量的概率分布也可以因此得出。接着是转录层CTC,在这里,需要将RNN的输出转换成字符串序列。
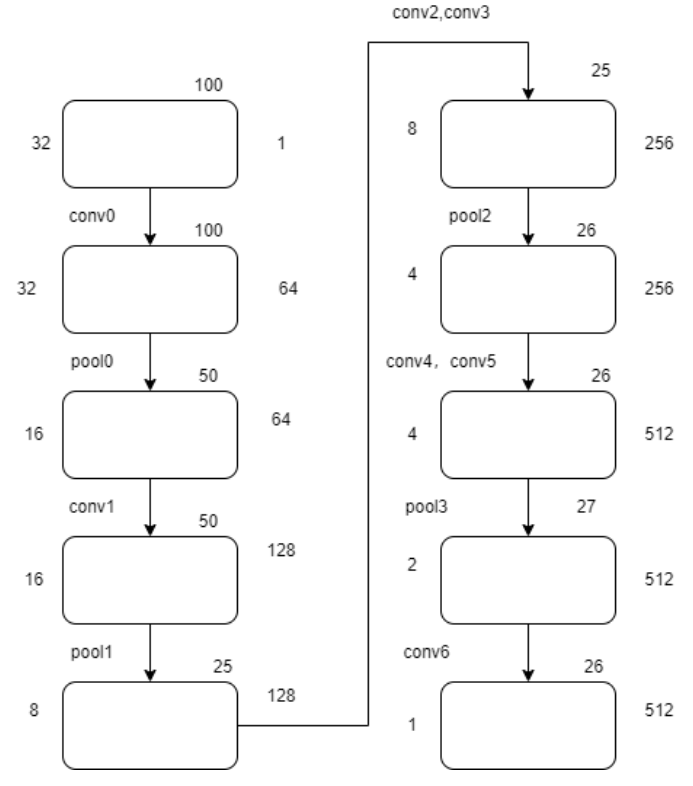
卷积层的工作,首先将所有输入的图片Resize之后变成$100 \times 32$ 大小。再将图片传入到网络模型当中,进行不断卷积,每一个特征图(Feature Maps)对应一个感受野(Receptice Field)。
循环层的工作,是将在每一个时刻,将一个特征图传入到RNN中。
RNN采用的是LSTM|,解决的是梯度消失问题,并且LSTM是双向的,容易预测具体的行为。例如这样的一句话:我的手机坏了,我想要XX新手机。对于这一句话,如果是单向的话,那么从前往后,只能得到一个“我的手机坏了”,这一个信息,而在后半段前面部分的“我想要”这里,无法判断是需要修手机还是买手机。而双向从后往前,先得到“新手机”这一个信息,因此能够推断出是需要买一个新手机。
对于标签概率分布,则是每一列的概率加起来为1。例如第一个时刻,分别预测a-z可能的概率,所有情况加起来为1。将预测结果全部转化成一个字符串序列。
转录层的工作,这里使用了Lexicon-based,也就是对于每一个预测使用例的输出,都进行了一定限制,只能在固定的label序列中进行选择,相当于有一个拼写检查的过程,使得准确率更加高。例如a-z识别,需要在前面加入一个空白符。$\pi=—hh-e-l-ll-oo—$ 这种情况,相邻相同只取一个,去掉空字符,最后可以得到的$B(\pi)=hello$ 结果。并且不止只有一条路径为hello,可能很多条,需要把所有路径概率加起来,其中每条路径概率为所有选取空格概率乘积。
最后可以得到一个推而广之的公式:
然后是代码的一些实现,在下方的函数传入中,可以看到几个参数。其中,imgH为图片的高度;nc代表了输入图片通道数。如果是灰度图,那么只有一个通道,为单通道。如果是RGB,那么有三种颜色来描述,即为三通道;nclass为分类数目,例如需要识别a-z,再加上一个空白符;nh为隐藏神经元节点个数,通常设置为256;leakyRelu代表是否使用leakyRelu激活函数,这里不进行使用了。
def __init__(self, imgH, nc, nclass, nh, leakyRelu=False):
这里尺寸的计算为以下的公式:
接下来,即是对图片进行卷积操作,卷积过程如下图所示:
之后是LSRM类,在这里nIn为神经元个数,nHidden设置为256,bidirection设置为True代表采用双向结构。
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
训练及运行
训练
对于一个深度学习的项目来说,训练是不可少的一步工作。首先,需要一张显卡,建议最低要求是GTX960,显卡越好,训练的速度越快,时间也可以得到大大的缩短,因此在本项目中,我们选取的是GTX30系显卡中的GTX3060版。
需要在训练的相关模块中,加入数据集的信息,确保数据集能够载入。
1 | train_txt_file=os.path.join(base_dir,r'D:/Code/Python/invoice/VOC2007/ImageSets/Main/train.txt') |
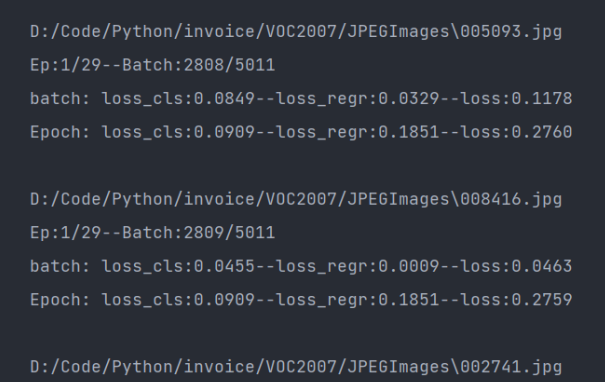
我们可以看到,这里一共是5011个数据集,一共是29轮的训练周期,图片中为第一个周期的第2809张图片的训练片段,可以看到,这里loss损失为0.09左右,还需要进行优化,降低loss才可以。
为了保证训练过程中,不因为外部因素而产生中断的结果,这里需要编写中断保存的功能,即在每一个周期结束之后,进行保存,这样可以保存上一个已经结束的周期,然后将模型的信息进行更改,这样下次进行训练的是否,就会从中断的位置再开始了。但是对于一个周期内运行的进度,则会丢失,导致该周期训练的图片,需要从头开始运行。因此建议一个周期训练完整结束之后,再进行保存操作。
1 | # if epoch % 30 == 0 and epoch != 0: # 保存模型 |
最开始,我们的这个项目,花费了300个小时,但是最后训练模型效果并不理想,在寻找原因最后,得出结论,应当是训练的数据集产生了问题。于是又对数据集进行了图像处理,增加了图像的多样性。然后再一次进行训练,这次训练花费10小时,loss损失降低到了可控的范围之内。
模型加载
训练完毕之后,会产生多个pth格式的文件,将这些文件放在指定的模型存放位置即可。
运行结果
在Pycharm中,选中主程序,点击右上角的运行按钮进行运行。

可以看到,在终端中,开始输出识别的结果,识别出我们需要的信息。
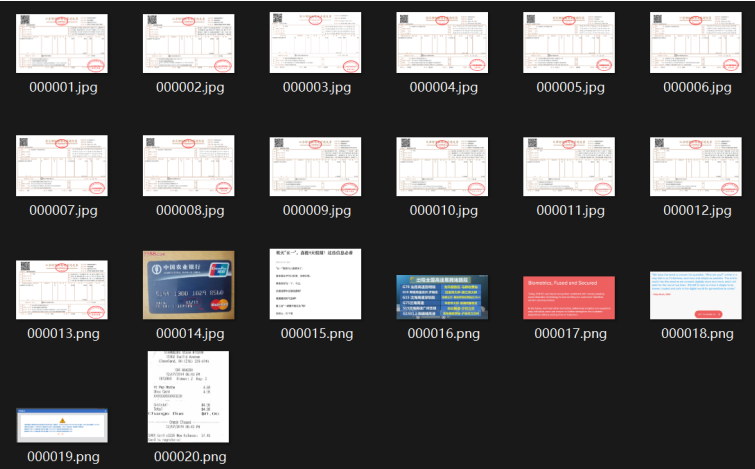
这里关于识别对象的选取,首先是13个增值税发票,此处的发票为日常出行的记录,然后又加入了一些通用文字的测试。
输出增值税发票识别结果
在识别结果中,可以看出,识别结果大致都保持在80%以上,结果的效果还是可以的。不过,对于一些带有特殊字符的地方,识别结果可能会徘徊在60-70%这个区间,甚至说,会降低到60%以下的情况,而这些识别精度较低的区域,并不是一张发票的有效信息,我们所需要的信息,在上方与中间,此处的识别准确率较好。
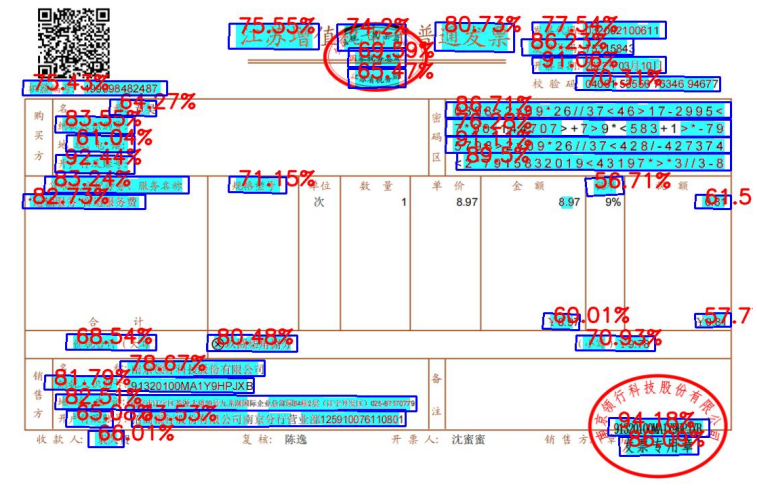
在识别测试之后,将识别结果中的txt数据进行读取,然后将其写入到表格当中,便于数据的获取。

输出银行卡识别结果
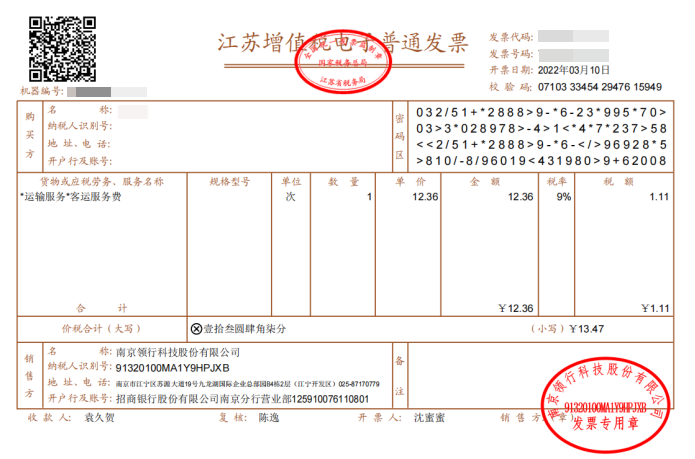
用此模型,进行了额外的测试,由于发票通常是和银行卡一块配合使用的。因此,用这个模型,对银行卡进行了识别的测试。可以看到,对于一些色块分布较为明显的地方,识别准确率基本维持在90%以上。而某处,红蓝色块的交替,导致了识别结果会降低到70%左右的程度。

结论
本项目先利用CTPN网络识别发票的文本区域,随后把文本区域输入CRNN网络,以做免分割的端到端鉴别,克服了传统字符分割上的困难,最终实验准确率达90% 左右,响应时间为100 ms 左右,效果良好,达到了预期目标。
在中期的训练问题上,花费了一些时间,一开始选取了中文数据集进行训练,在得到一个模型之后,应用于项目之中,但是在使用的是否,遇到了效果不佳的情况,遂而改变数据集,选用VOC比赛所使用的数据集进行训练,识别结果相对于前者来说,有不错的提高。另外一个问题,就是训练时间过长,也导致了效果的不理想,这一点主要是由于数据集单一导致的,建议在数据集选取上,尽可能选取不同内容数据集,这样才能使得最终效果有明显的提升,也能有效缩短训练时间。
本项目后期识别结果,大部分在预期之中,但是少量情况,识别精度较为底下,并不能准确识别出来,导致结果是一些无法判断的字符,或者会产生残缺等问题,因此,本项目的一些不足之处,还需要在日后的学习当中,再进行优化处理。
致谢
感谢杜兰老师,在过去垂青于我,给了我机会,使我能够接触到视觉学习领域的知识,在过去的时间里,跟着杜老师,完成了省创和校创的项目,并且参与了学校毕业设计的金种子项目。同时,感佩杜老师,在交流过程中,学术功力的强大之处,能否在前期为我的学习指明道路,引导我不断学习。同时,杜老师和蔼可亲,因材施教,沐风栉雨的风格,让我在学习当中,如沐春风。杜老师真可称为一位负责任,有耐心的好老师,无以为报,再次感谢。
弹指一挥二十载,如今已是毕业人。莫问前程在何处,路在脚下走便是。
参考文献
- 左捷.推行增值税电子专用发票的思考[J].知识经济,2020(12):36-37.
- 邵慧敏,张太红.基于CTPN神经网络对营业执照文字检测模型[J].计算机技术与发展, 31(01):94-97.
- 朱莉莉,刘芳芳.浅谈现代通信技术及其发展趋势[J].电脑知识与技术,2013,9(11):2584-2585+2588.
- 辜双佳,栗智.基于CRNN模型的中文场景文字识别[J].科技风,2021(17):108-110.
- 刘艳菊,伊鑫海,李炎阁,等.深度学习在场景文字识别技术中的应用综述[J].计算机工程与应用,2022,58(04):52-63.
- 王栋.人工智能OCR技术的应用研究[J].电子技术与软件工程,2022(01):122-125.
- 刘丹,王少康,张同社. 一种图像分层压缩方法及图像分层压缩装置[P]. 北京市:CN113365071A,2021-09-07.
- 付童. 端到端的自然场景文字检测与识别研究[D].北京:北京交通大学,2020.
- 张正夫. 基于深度学习的场景文字检测与识别方法研究[D]. 北京:中国科学院大学(中国科学院深圳先进技术研究院),2020.
- 白志程,李擎,陈鹏,等.自然场景文本检测技术研究综述[J].工程科学学报,2020,42(11):1433-1448.
- 杨捷,刘进锋.利用CTPN检测电影海报中的文本信息[J].电脑知识与术,2018,14(25):213-215.
- 孙光民,关世奎,李煜,等.基于改进CTPN算法的试卷手写文本检测[J].信息术,2020,44(09):94-98.
- 王之博,赵双明.基于Mask R-CNN的道路交通标志识别[J/OL].测绘地理信息:1-4[2022-05-18].
- 程学军,邢萧飞.利用改进型VGG标签学习的表情识别方法[J].计算机工程与计,2022,43(04):1134-1144.
- 马森标,唐卫明,陈春强.LSTM优化模型的水库水位预测研究[J].福建电脑,2022,38(05):1-8.
- 王卫中,周铭辉,李丹丹.CT联合CTC检测对GGO患者早期肺癌的诊断价值[J].中国CT和MRI杂志,2022,20(01):71-72+115.
 支付宝
支付宝 微信
微信