开题报告
文献综述
- 增值税发票增值税专用发票是商事凭证,由于实行凭发票购进税款扣税,购货方要向销货方支付增值税,因此也是完税凭证,起到销货方纳税义务和购货方进项税额的合法证明的作用,是增值税普征性和公平性的体现:每个环节征税,每个环节扣税,让税款从上一个经营环节传递到下一个经营环节,一直到把商品或劳务供应给最终消费者,这样,各环节开具的增值税总额,就是该商品或劳务的整体税负,体现了增值税普遍征收和公平税负的特征[1]。
- 在当前移动互联网快速发展的大环境下,增值税发票识别成为一个比较热门而有价值的应用方向。并且伴随着社会信用体系不断完善,增值税发票已经成为人们主流的交易证明。在现代科学研究、军事技术、医学、工农业生产等领域,越来越多的人使用图像信息来识别和判断事物并解决实际问题,在此环境条件下如何高效有序地对增值税发票进行智能化管理,是对当下智能票据提出的一个硬性要求。发票号码作为发票唯一的身份标识,常用作支付交易证明和经费报销申请的主要依据,所以针对发票识别技术(Invoice Recognition Technology,IRT)[2],从传统的机器学习到当下的深度学习都在不断地进行着算法的更新与迭代。因此在当今科学技术高速发展的时代,对增值税发票识别的处理技术就有了更高的要求,能够更加快速准确地检测人们所需的图像文本信息[3]。
- 目前CVPR、ICCV、ECCV等国际顶级会议,已将场景文字检测与识别列为其重要主题之一,文字检测与识别技术广泛运用在图片识别方面,是当前研究的前沿课题。场景文字识别(Scene Text Recognition,STR)[4]是在各种复杂情况下将图像输入翻译为自然语言输出,需要包括文字检测和文字识别两个步骤,文字检测即发现文字的位置和范围,文字识别即将文字区域转化为字符信息。文字识别技术对人类来说是非常具有挑战性的领域,尽管文字识别技术发展缓慢,但人类为了实现技术普遍应用到生活中的各方面也一直在为之奋斗着。因为文字识别技术不仅有利于其他技术的发展并且文字识别技术的发展领域非常广泛,其中光学字符识别(Optical CharacterRecognition,OCR)识别技术在文字识别领域中是项重要技术。
- 发票识别检测的主要目的是从复杂的发票布局环境中检测出发票的有效区域。通过Sobel算子进行发票边缘检测[5] 。在进入21世纪后,计算机算力实现了巨大的飞跃,深度神经网络和计算机视觉开始广泛应用于发票文字检测之中,其中比较成功的是基于卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)和连接主义文本建议网络(Connectionist Text Proposal Network,CTPN)[6]实现的算法。
- 传统的发票识别是由预处理和图像输入组成的,预处理方法包含灰度化和二值化及图像矫正,还有去除噪声等等[7],图像输入对不一样的压缩方法,有不一样的存储方法等等。关于企业衡量发票识别性能的好与坏的指标分析主要有产品的稳定性、易用性、可行性、误识率及识别速度的问题等等,并用相关辅助数据来提升识别的准确率,这在发票识别信息技术中是非常重要的[8]。简略的讲就是把文字转化成图像数据,而后运用字符识别将图像数据转换成能够应用的输入技术。并对发票识别的结果实行剖析后智能纠正错误结果。随着中国的科技发展愈来愈好,发票识别信息技术随之也普遍运用起来。
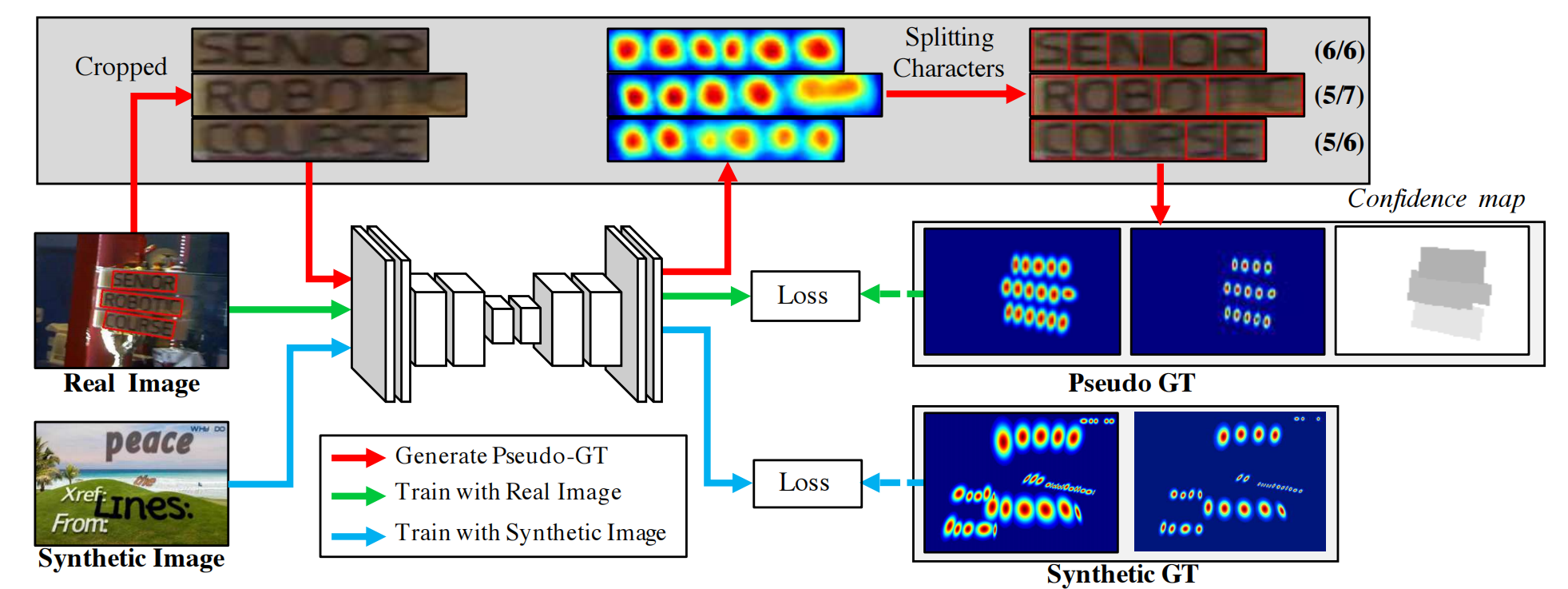
- 在实际应用中,发票文字的检测和识别往往串联在-起,能同时检测到文字位置并对其进行识别的方法被称为“端到端”文字识别方法[9]。由于中文场景中存在背景干扰、字体模糊、遮挡等多种复杂情况,中文场景文本识别面临更多的挑战因不同类型的发票的大小、颜色均不同,所以本文首先进行的是分类,确定发票的类别,这样如火车票这种字符像素固定的发票,就可以采用固定的模板截取出待识别信息的图像,同时降低了后续识别的难度。其次针对增值税这种机打字符像素随打印机的不同而变化的发票,将使用基于图像增强的二次分割法,用于实现截取,并进行倾斜校正。这样既降低了识别难度,又提高了发票识别的准确率[10]。
- 近几年,国内外大量的专家学者们也关注到了这个方面。Wang[11]等最早提出用深度学习的方法实现文字检测,用卷积神经网络对每一处滑动窗进行分类。但这类方法算法复杂度高又不能够完全实现端到端的训练和测试。Zhou[12]等提出支持多方向文字定位的EAST网络,该方法可以检测各个方向的文字,但是对较长文字检测效果不佳,感受野不够长。杜薇[13]等人在验证码识别研究中指出字符分割有很明显的弊端,如在文字重叠度高且文字结构不规范时分割难度较大,准确率低、效率低等问题。
- 目前,文字检测方法主要包括基于文本框回归的分类、基于分割的回归以及分割和回归结合的方法[14]。虽然近些年基于深度学习的文字检测方法已经取得巨大进步,但是文字作为一种具有其独有特色的目标,其字体、颜色、方向、大小等呈现多样化形态,相比一般目标检测更加困难[15]。一个模型在某个开源的数据集上得到了很好的效果,用这个方法直接换到另外的数据集上也许效果就不是很好,甚至是比较差的。因为很多模型是针对某项数据集来调整参数进行不断优化的,所以它极大依赖于数据,深度学习它有没有学到本质的东西,这个问题还值得深度探讨[16]。神经网络模型在文字检测方面已经有了研究,例如区域文本框网络(Region Proposal Network,RPN),只是RPN进行的文字检测很难准确地进行水平检测。RPN是通过直接训练来定位图像中的文本行,但是通过文本行来预测图像中的文本出现错误的可能性很大,因为文本是个没有明确的封闭边界的序列。令人欣喜的是,Anchor回归机制[17]的提出允许RPN可以使用单尺度窗口检测多尺度的对象,这个想法的核心是通过使些灵活的Anchors在大尺度和纵横比的范围内对物体进行预测。其研究结果表明,根据CTPN方法,建立增值税发票文字检测神经网络模型,能够准确地对增值税发票的文字进行水平检测。
参考文献:
[1] 唐军,唐潮.增值税发票信息结构化识别[J].计算机系统应用,2021,30(12):317-325.
[2] 杨蕊,杨洁.基于图像分析的发票识别与管理系统[J].计算机时代,2020(10):4-8.
[3] 白翔,杨明银,石葆光,等.基于深度学习的场景文字检测与识[J].中国科学(信息科学),2018,48(5):531-544.
[4] 辜双佳,栗智.基于CRNN模型的中文场景文字识别[J].科技风,2021(17):108-110.
[5] 杨华.基于Sobel算法的塑料袋边缘位置标定[J].包装工程,2021,42(23):178-182.
[6] 郝聚涛,段静文,陈超,陈鸿龙.一种基于CTPN网络的文档图像标题检测算法[J].电子技术与软件工程,2021(05):175-176.
[7] 斩振伟.基于CTPN的网店工商信息提取系统的研究和实现[J].现代信息科技,2018,2(11):27-28.
[8] 王梦迪,张友梅,常发亮.基于边缘检测和特征融合的自然场景文本定位[J].计算机科学,2017,44(9):300-303.
[9] 邱晓欢,吴啟超.一种基于改进EAST网络和改进CRNN网络的火车票站名识别系统[J].南方职业教育学刊,2019,9(6):81-88.
[10] 曹长玉,郑佳春,黄一琦.基于区域卷积网络的行驶车辆检测算法[J].集美大学学报:自然科学版,2019,24(4):315-320.
[11] WANG T,WU D J.COATES A,et al.End-to-End Text Recognition with Convolutional Neural Networks.2012 International Conference on Pattern Recognition(ICPR 2012),2012.
[12] ZHOU X,YAO C,WEN H,et al.EAST: An Efficient and Accurate Scene Text Detector[J].2017.
[13] 杜薇,周武能.基于CTC模型的无分割文本验证码识别[J].计算机与现代化,2018(09): 48-51.
[14] 杨国亮,王志元,张 雨,等.基于垂直区域回归网络的自然场景文本检测[J].计算机工程与科学,2018,40(7):1256-1263.
[15] 戈嘉宇,刘为嵩.基于深度学习的身份证识别系统的设计与实现[J].电子世界,2020(2):109.
[16] 杨捷,刘进锋.利用CTPN检测电影海报中的文本信息[J].电脑知识与技术,2018,14(25):213-215.
[17] 张 勋,陈 亮,朱雪婷,等.基于区域卷积神经网络FasterR-CNN的手势识别方法[J].东华大学学报:自然科学版,2019,45(4):559-563.
研究问题和拟采用研究手段
研究问题
- 近年来基于深度卷积神经网络的发票文本识别方法开始占据主导地位。其中循环神经网络在具有依赖性的上下文序列化信息的发票文本识别表现突出。其中包含记忆功能机制的识别方案主要采用”code-encode”的框架即编解码的框架结构。基于CTC损失函数的识别模型,首先利用CNN进行文本特征提取,然后利用RNN对文本特征序列化依赖信息进行建模,最后利用CTC损失函数进行预测,得到文本序列。这种序列到序列的方法能够更好的结合上下文的文本信息,对后续的文本行进行合理预测,能够将每一段的预测值再筛选留下对应的文本行信息,这样转出来的文本序列准确率更高。
拟采用研究手段
现阶段,深度学习的框架已经出现了几十种,例如常用的CNN和RNN网络,以及深度信念网络等,它们能够应用于发票文本识别领域主要得益于以下的两种经典算法。
- 第一种就是AlexNet,AlexNet由Alex Krizhevsky 创建,一共有八层网络,由5个cov层和3个FC(全连接)层构成的。AlexNet创造性的引用了droput的框架模式,使其在进行文本识别时,能够保证特征提取的结果错误率大大降低,为后续的卷积神经网络应用于文本识别开拓了新的方向。但是由于其网络层数过少,在应用于发票识别领域时,无法充分提取发票的粘滞文本特征,在紧密字符的识别上,准确率不高。
- 第二种就是VGGNet,全称为Visual Geometry Group Network,它由牛津大学的视觉几何组的Karen Simony 和Andrew Zissmen等人创建。VGG相较于AlexNet,它的网络层数共有22层。VGG的最大的特点在于使用了3x3的卷积核进行特征提取,这样使的网络层数更深,且特征提取更加的完善。而且在图像处理方面,数据增强的方式与AlexNet的单纯的旋转和反转不同,其采用了Multi-Scale方式,能够将所有特征提取后的图片统一处理为224x224大小的图片,这样统一大小后的图片能够使后续的预训练更加的迅速,而不会因为网络层数的变深导致训练速度变慢的情况。综上VGG的表现验证了不需要改变结构就能通过加深网络层数改善网络性能。
 支付宝
支付宝- 微信